Оценка генеративного ИИ для научных исследований с помощью открытого бенчмарка

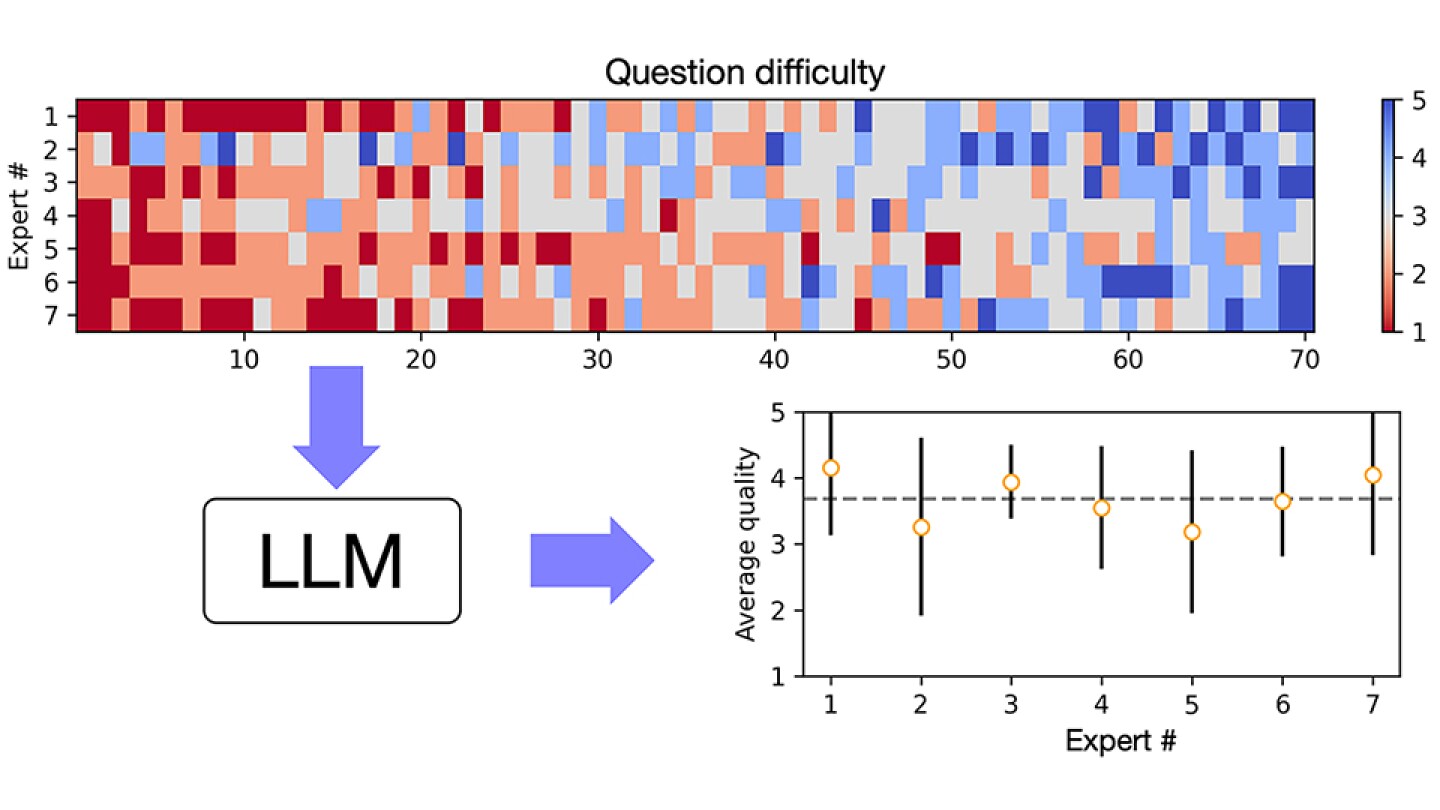
Исследование генеративного искусственного интеллекта (ИИ) с помощью открытых бенчмарков показывает как его потенциал, так и недостатки. В недавней работе группы исследователей, возглавляемой Эйвери Томпсоном, был разработан открытый бенчмарк для оценки больших языковых моделей (LLM) в контексте осаждения атомных слоев (ALD). Это отличный пример использования оценок ИИ для научных исследований.
Оценка больших языковых моделей в научных исследованиях
Большие языковые модели представляют собой последнюю итерацию генеративных нейронных сетей, способных создавать текст, звучащий как человеческий. Они могут отвечать на заданные вопросы. Но точность и полезность предоставляемой информации, особенно в технических областях, остаются под вопросом. В отличие от традиционных бенчмарков, которые часто требуют четкого и правильного ответа, открытые бенчмарки помогут оценить более сложные аспекты. Например, такие как актуальность и полезность ответов. Именно здесь важно провести оценку ИИ для научных исследований.
Группа исследователей, включая Анжела Янгуаса-Гила, собрала список из 70 вопросов по ALD. Он охватывал уровень от начального до продвинутого. Каждому вопросу был задан LLM, ChatGPT 4o. Ответы оценивались по критериям качества, специфичности, актуальности и точности. Результаты показали, что хотя модель в основном давала правильные ответы. Однако, с более сложными и специфическими вопросами она сталкивалась с трудностями. Это подчеркивает недостатки, которые могли бы остаться незамеченными при использовании традиционных бенчмарков. Оценка ИИ для научных исследований в таких условиях становится ещё более важной.
Роль открытых бенчмарков в оценке возможностей ИИ для науки
Анжел Янгуас-Гил отметил: «Открытые вопросы помогли нам тестировать различные аспекты генерации ответов, помимо точности, которые действительно важны для научных приложений». Это открытие подчеркивает важность использования открытых бенчмарков для оценки ИИ в научных исследованиях. Также показывает их потенциал в других областях.
Работа, опубликованная в Journal of Vacuum Science and Technology, представляет собой важный шаг. Это шаг в направлении более глубокого понимания возможностей и ограничений LLM в научных исследованиях. Исследователи надеются, что этот бенчмарк послужит шаблоном для других научных областей. Это позволит оценить эффективность LLM в своей работе.
Таким образом, открытые бенчмарки могут существенно улучшить нашу оценку генеративного ИИ. Они позволяют выявить его возможности и ограничения в реальных научных приложениях. Это важный шаг вперед в развитии технологий, которые могут изменить подход к научным исследованиям. Безусловно, нужна тщательная оценка ИИ для научных исследований. Это поможет определить его будущее использование.
Источник: AIP

Похожие статьи

Исследование Центра письма и политики ИИ в LMU показывает, как искусственный интеллект влияет на процесс обучения.

Рынок ИИ в телекоммуникациях достиг 2,36 миллиарда долларов и продолжает расти. Узнайте, что это значит для будущего.

ИИ в управлении фибрилляцией предсердий может значительно улучшить результаты лечения. Узнайте больше о его применении.

Разборы, как AI снижает цену заявки
